Speed, Accuracy, and Visibility - Instruction Set Simulation without compromise!
Instruction set simulators (ISS) are vital tools for compiler, operating system, and application development as well as processor architecture design space exploration and verification. Because the demands are so different, designing an ISS that caters to all of the above application scenarios is a constant challenge. On the one hand HW verification demands absolute precision with respect to architectural behavior. Even for corner case randomly generated scenarios that are unlikely to occur in reality. Compiler developers on the other hand require functional correctness, performance, and rich profiling feedback to create an optimizing compiler before the actual HW is ready.
In this context it is easy to settle for a compromise, trading architectural accuracy for performance. At Synopsys we have chosen not to settle and to provide one product that can do it all without compromise - namely DesignWare ARC nSIM. nSIM is ``the tool'' within ARC SNPS that is extensively used by ALL our teams for ALL stages of HW and SW development. In this article we will shine the spotlight on two very important features of nSIM, namely (1) simulation performance and (2) architectural accuracy. To achieve the highest possible simulation performance where simulation speed exceeds the speed of final silicon, we apply cutting edge Just-In-Time (JIT) compilation technology. To guarantee architectural accuracy we have designed nSIM to integrate into our RTL verification methodology in a novel way that not only speeds up our internal verification process, but also guarantees architectural correctness at the simulation level by design.
Turbo charging simulation performance
Dynamic compilation, also referred to as Just-In-Time (JIT) compilation, is the key technology to speed up simulation of programs at runtime. The key idea behind dynamic compilation is to defer machine specific code generation and optimization until runtime when additional profiling information is available. Some optimizations that are critical for high-performance simulation speeds are virtually impossible to apply without dynamic runtime information. The rule of thumb is that a dynamic compiler will roughly yield up to 10X speedups when compared to interpretive simulation performance (see Figure 1).
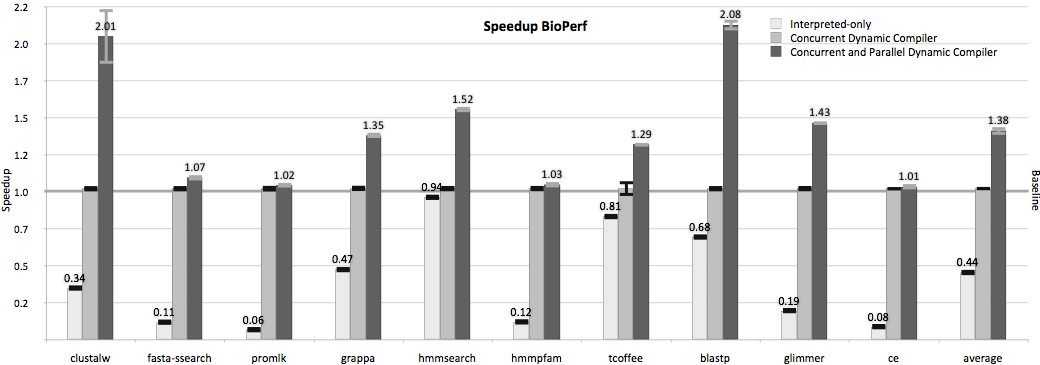 Figure 1: Speedups for BioPerf benchmark suite comparing (a) nSIM base interpreted only simulation mode, (b) nSIM Pro simulation using a single concurrent dynamic compiler, and ( c) simulation using nSIM Pro’s novel, concurrent and parallel dynamic compiler.
Figure 1: Speedups for BioPerf benchmark suite comparing (a) nSIM base interpreted only simulation mode, (b) nSIM Pro simulation using a single concurrent dynamic compiler, and ( c) simulation using nSIM Pro’s novel, concurrent and parallel dynamic compiler.
Dynamic compilation occurring at runtime inevitably incurs an overhead and thus contributes to the total execution time of a program. There is a trade-off between the time spent for dynamic compilation and total execution time. If, on the one hand, lots of effort is spent on aggressive dynamic compilation to ensure generation of highly efficient native code, too much compilation time will be contributed to the total simulation time of a program. If, on the other hand, too little time is spent on optimizing code for execution during dynamic compilation, the runtime performance of the simulated program is likely to be suboptimal. Three key innovation behind nSIM Pro dynamic compilation infrastructure aim at reducing dynamic compilation latency thereby speeding up simulation by (1) adaptively prioritizing the hottest most recently executed program regions to be (2) compiled in parallel, (3) concurrently with the simulation of the target program.
During simulation we only want to invest dynamic compilation effort for program regions that are executed frequently, but what ``executed frequently’’ means depends on the application. Traditionally dynamic compilation systems used an empirically determined threshold or left if up to the user to select a threshold. The problem is that we do not know which programs users are going to run and we can’t expect users to waste time figuring out what the right threshold would be for their application. Therefore nSIM removes this burden by adapting its program hotspot selection strategy automatically. That means it is guaranteed to yield the best performance for small embedded benchmarks such as EEMBC CoreMark, as well as large benchmarks such as the simulation of the GCC C compiler included in the SPEC CPU 2006 benchmarks.
To effectively reduce dynamic compilation latency, a dynamic compilation system must improve its workload throughput, i.e. compile more application hotspots per unit of time. To achieve this goal in nSIM we analyze profiled code and JIT compile independent translation units in parallel. Furthermore we never pause the simulation to wait until the JIT compiler has finished generating code for a particular program hotspot. Instead we continue interpretive simulation concurrently with dynamic compilation, further hiding dynamic compilation overheads. For the user this means there are no unpleasant pause times and simulated applications are snappy and responsive which is really important when simulating applications that require real time simulation performance (e.g. SNPS DesignWare Audio Codec IP) or user interaction (e.g. full system OS simulation).
A novel way to dynamically discover and select program regions coupled with parallel and concurrent dynamic compilation makes nSIM a truly scalable simulator, capable of automatically adapting to changing workloads, efficiently exploiting parallelism and concurrency available on contemporary multi-core simulation hosts. Figure 1 clearly demonstrates the speedups achievable by the concurrent and parallel dynamic compiler built into nSIM Pro when compared to the free nSIM base version that only includes an interpretive simulator using the BioPerf benchmark suite.
Simulator behaves like real Hardware
It is extremely important that a processor simulator behaves like the final Hardware product to avoid unpleasant and costly surprises late in the development cycle. Therefore we spend a lot of time and effort making sure nSIM and RTL match precisely by exclusively relying on a verification methodology that deeply integrates nSIM into the Hardware verification process as ``The Golden Master Model’’.
Every new ISA feature is implemented in RTL and nSIM based on the description present in the programmers reference manual. Finally, during verification, both RTL and nSIM are executed in lock-step, comparing detailed architectural and micro-architectural state of the RTL and nSIM models after each step. This verification methodology is also commonly referred to as Online or Co-Simulation verification.
Every second we run thousands of randomly generated as well as directed tests using Co-Simulation, making sure RTL and nSIM are in sync and behave correctly. Compared to an offline verification strategy online verification significantly speeds up the verification process as it can pin-point errors instantly and precisely. There is no more need to perform time consuming post-mortem analysis of trace files that can never carry as much state information as is available at runtime. Furthermore, due to the fact that offline verification relies on the presence of instruction traces, it is bound by mundane but very real limits such as file size and file storage. Co-Simulation does not suffer from this problem and can easily stress test RTL and nSIM simulating many billion instructions yielding better test coverage for both RTL and nSIM.
Because of this deep integration of nSIM into the RTL verification process, nSIM users can rely on the fact that the programs they develop using the nSIM simulator will behave the same on final Hardware. This is true even for the most obscure corner cases that most of our users will most likely never run into, but which must be tested and verified during RTL development.